Is Robots.txt Blocking the Right Files on My Site?

By default, all the URLs on your site can be crawled by Google. However, if we don’t want Google to index some specific pages, you can use a robots.txt file.
In your Robots.txt file, you can request that Google not index certain pages by using this “disallow” rule:
Disallow: /dont-scan-this-url/In this post, I’ll show you how to use Google Search Console to check whether you have successfully blocked Google from indexing a particular URL.
Step #1. Check if a URL is disallowed
In order to use this tool, you will need to have your site verified in Google’s Search Console.
- Go to the Robots.txt Tester page.
- Choose a verified property from the list. If your site is not listed, click “Add property now”; continue that process and come back to this tutorial when it’s done.
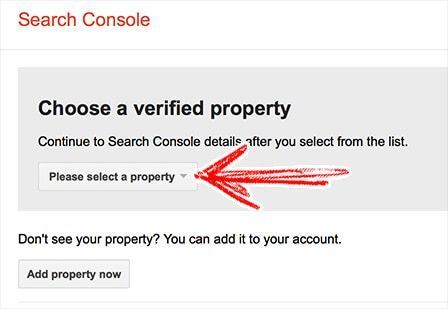
The next screen will load the content from your robots.txt file, located at www.yoursite.any/robots.txt. The location of this file will be the same, whether you use WordPress, Drupal, Joomla, or another platform.
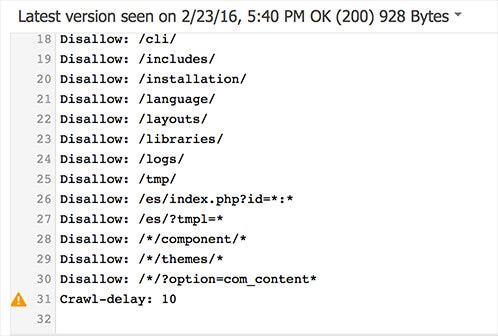
Below, type a URL to confirm if indeed was disallowed correctly in robots.txt.

- Choose the search bot; leave “Googlebot” by default.
- Click the “Test” button.

If a Disallow rule matches this URL, it will be shown in red, and “Test” switch to “Blocked”.

This confirms the tested URL won’t be indexed by Google.
How to Disallow URLs with a pattern
It is easy to disallow a single URL, however, what about disallowing a bunch of URLs that match a pattern?
Let’s clarify with an example. I want to disallow these pages:
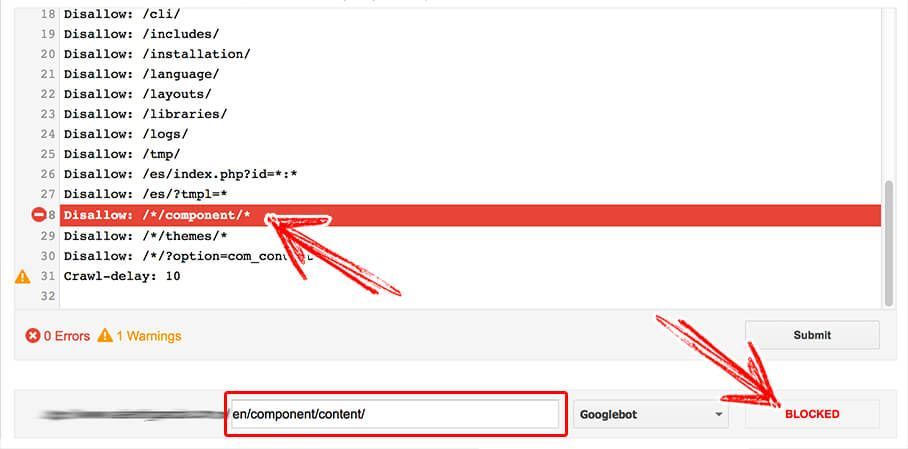
- www.yoursite.any/en/component/content/
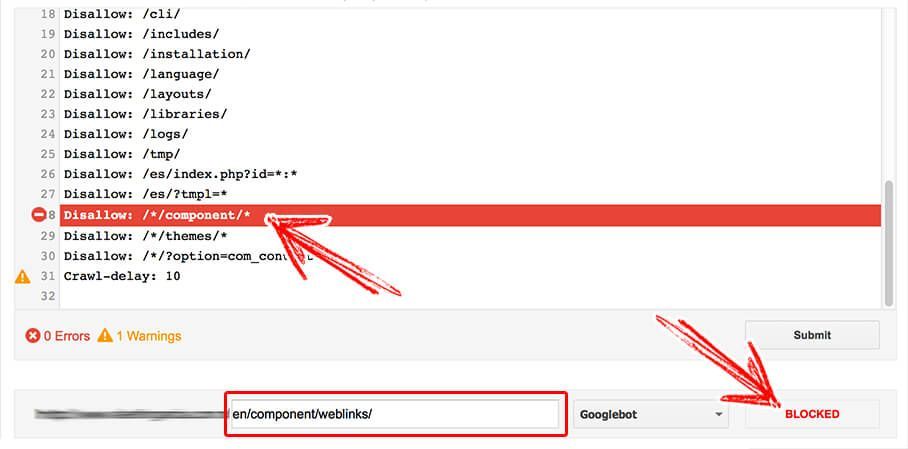
- www.yoursite.any/en/component/weblinks/
- www.yoursite.any/fr/component/content/
- www.yoursite.any/fr/component/weblinks/
Certainly, I could just add 4 lines in the robots.txt file, one for each URL. But I can get the same result with a single line that targets all those pages by taking advantage of the pattern:
Disallow: /*/component/*The syntax would match the 4 URLs above. In this context * are variables that replace the bold characters from the above list of pages.
Confirm the rule works using the process we explained in Step 1. I my example, the 4 URLs are successfully disallowed by the same rule:
- www.yoursite.any/en/component/content/
- www.yoursite.any/en/component/weblinks/
- www.yoursite.any/fr/component/content/
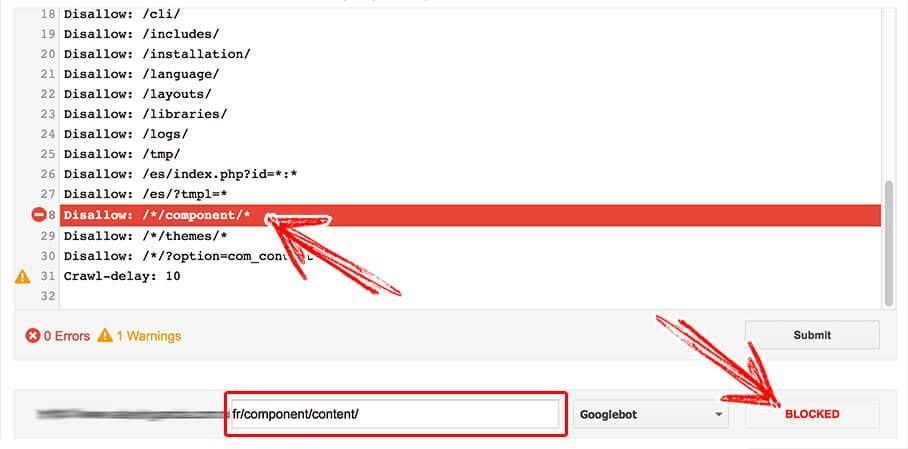
- www.yoursite.any/fr/component/weblinks/

There is an error in this article based on a misconception. Disallowing the crawler from accessing a page or path via robots.txt does not mean that crawler will not still index the given page or path. If a crawler follows a link from a third party website to your page — it can still index the page if it chooses to. Just remember, robots.txt controls the crawler. HTML meta tag “robots” and HTTP header codes “X-Robots” can control the indexing behavior. I hope this helps! – Tanner Williamson